3. Results: Whole Brain (316 ROIs)¶
3.1. Search Grid With 5-fold Cross Validation¶
In order to make the model generalizable and avoid overfitting, hyperparameters like: 1) L2 regularization, 2) dropout, and 3) learning_rate were optimized using a k-fold nested cross-validation method. Seventy-five different combinations of the aforementioned hyperparameters were used to train and validate the model. Figure below shows the training and validation set performance of the 75 models. The models are arranged in the descending order of their mean validation accuracy. The error bars indicate standard deviation across folds. As the number of classes in the dataset were balanced, accuray was an appropriate metric to evaluate the model performance.
import pickle
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context="talk",style='whitegrid')
import pandas as pd
import numpy as np
np.random.seed(42)
import tensorflow as tf
import os
from joblib import dump, load
from src.preprocess.dataset import *
from src.models.model_selection import classifier
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import plotly
import plotly.graph_objs as go
%matplotlib inline
with open("../../results/00-ROI316_last_segment/grid_search.pkl","rb") as file:
results, param_grid = pickle.load(file)
table = pd.DataFrame.from_dict({(i,j,k): results[i][j][k] for i in results.keys() for j in results[i].keys() for k in results[i][j].keys()}).T
table.reset_index(inplace=True)
table.rename(columns={'level_0':'model','level_1':'fold','level_2':'set',0:'acc'},inplace=True)
table['mod_num'] = table.model.str[5:].astype(int)
order = table[table['set']=='val'].groupby('mod_num')['acc'].mean().sort_values(ascending = False).index
plt.figure(figsize=(20,5))
sns.barplot(x='mod_num',y='acc',hue='set',ci='sd',data=table,
palette=['C0','C1'],order=order,errwidth=0.75,
errcolor='k',capsize=0.25)
plt.xticks(rotation=90,fontsize=12)
plt.xlabel('Model Index')
_=plt.ylabel('Accuracy')
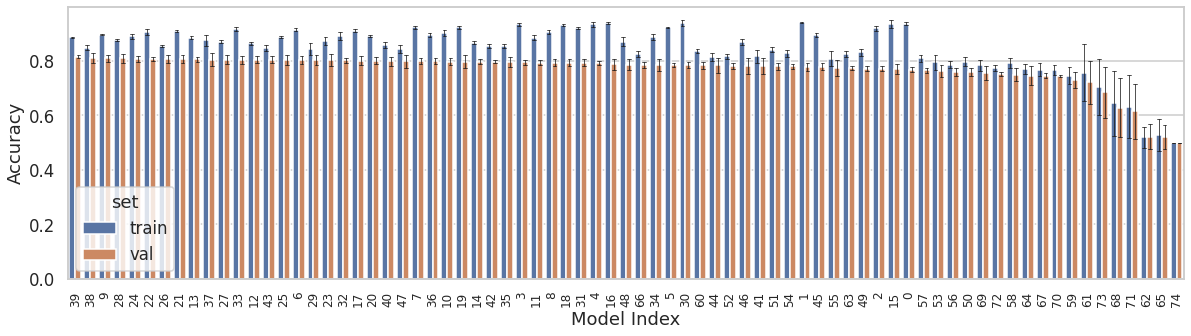
Best performing model yielded mean training and validation accuracies of 0.89 and 0.82, respectively. Its hyperparameters were: 1) L2 = 0.003, dropout = 0.3, and learning_rate = 0.001.
# load data
dataset = Dataset('../../data/processed/00a-ROI316_withShiftedSegments.pkl')
dataset.load()
dataset_df = organize_dataset(selective_segments(dataset.data,5))
dataset.train_test_split_sid()
# Split the data into train and test sets
X_train, y_train = query_dataset(dataset_df,dataset.train_idx)
X_test, y_test = query_dataset(dataset_df,dataset.test_idx)
# load the trained model
model = tf.keras.models.load_model('../../models/00-ROI316_last_segment/CustomGRU.h5')
# Evalute the trained model on each participant from the training set individually
from collections import defaultdict
from sklearn.metrics import accuracy_score
test_acc = defaultdict(dict)
for subj_idx in dataset.test_idx:
subj = dataset.sid()[subj_idx]
X_test, y_test = query_dataset(dataset_df,[subj_idx])
y_pred = np.squeeze(model.predict_classes(X_test))
for tp in range(X_test.shape[1]):
test_acc[subj]['TP{:02d}'.format(tp)] = accuracy_score(y_test,y_pred[:,tp])
loss, acc = model.evaluate(X_test,y_test)
test_acc[subj]['overall'] = acc
test_acc_df = pd.DataFrame(columns=['Subj','TP','Accuracy'])
for SUB in test_acc:
for TP in test_acc[SUB]:
temp_df = pd.DataFrame([SUB, TP, test_acc[SUB][TP]], index=['Subj','TP','Accuracy']).T
test_acc_df = pd.concat([test_acc_df,temp_df],axis=0,ignore_index=True)
test_acc_df['Accuracy'] = test_acc_df['Accuracy'].astype(float)
3.2. Test Data Performance¶
3.2.1. Accuracy¶
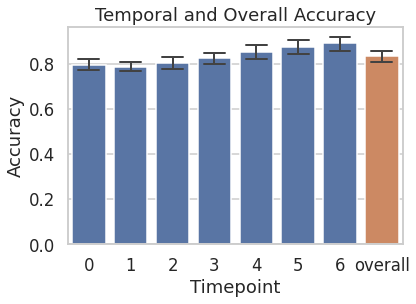
The trained model was tested on the near-miss segments of the 19 held-out participants. Following figure shows temporal and overall accuracies on the held-out participants. The model performs resonably well from the 1st timepoint (TP) itself, with a mean accuracy of 0.8. The mean accuracy steadily increases to 0.89 by the 7th TP. “Overall” accuracy is the mean accuracy across TP, which is 0.83.
sns.barplot(x='TP',y='Accuracy',data=test_acc_df,ci=95,palette=['C0']*7+['C1'],errwidth=2,capsize=0.5)
plt.xticks(ticks=np.arange(8),labels=list(range(7))+['overall'])
plt.xlabel('Timepoint')
_=plt.title('Temporal and Overall Accuracy')
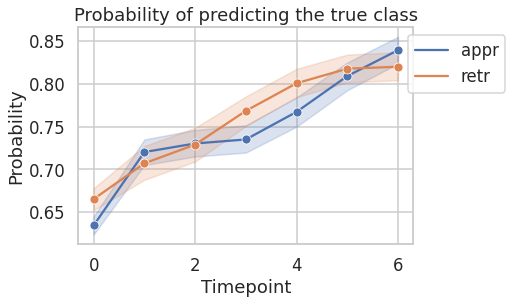
3.2.2. Probability of predicting the true class as a function of time¶
Following figure shows probability of predicting the true class as a function of time. The probability of predicting the true class increases with time.
## get probabilities of the true class at every timepoint
prob_df = pd.DataFrame(columns=['Subj','TP','class','prob'])
for subj_idx in dataset.test_idx:
subj = dataset.sid()[subj_idx]
for direction, k_class in zip(['appr','retr'],[1.,0.]):
X_test, y_test = query_dataset(dataset_df,[subj_idx])
X_test, y_test = X_test[y_test==k_class], y_test[y_test==k_class]
if k_class == 1.:
temp_df = pd.DataFrame(np.squeeze(model.predict(X_test)))
else:
temp_df = pd.DataFrame(1-np.squeeze(model.predict(X_test)))
temp_df['Subj'] = subj
temp_df['class'] = direction
temp_df = temp_df.melt(id_vars=['Subj','class'],var_name='TP',value_name='prob')
prob_df = pd.concat([prob_df,temp_df],axis=0, ignore_index=True)
sns.lineplot(x='TP',y='prob',hue='class',data=prob_df,
ci=95, markers=True,marker='o',dashes=False,
hue_order=['appr','retr'],palette=['C0','C1'])
plt.xlabel('Timepoint')
plt.legend(loc='upper right',bbox_to_anchor=(1.3,1))
plt.ylabel('Probability')
_=plt.title('Probability of predicting the true class')
3.3. Chance Accuracy¶
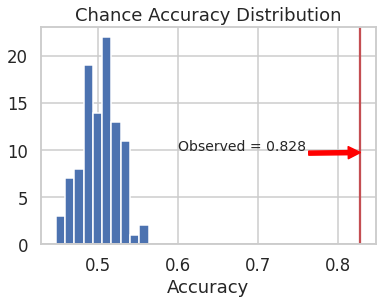
To assess significance of the observed test accuracy of 0.83, the observed test accuracy was compared against chance accuracy. Chance accuracy is obtained when the model predicts one of the two classes at random. To simulate a chance accuray distribution, the model with best hyperparameter settings was trained on the training data a hundred times, each time with shuffled labels. At every iteration, the model was tested on the test data with non-shuffled (i.e., true) labels, and the accuracy was recorded. From the chance accuracy distribution, it was found that the chance of achieving an accuracy of at least 0.83 was less than 0.009. See the figure below.
with open('../../results/00-ROI316_last_segment/perm_acc.pkl',"rb") as f:
obs_acc, results_perm = pickle.load(f)
plt.hist(results_perm['val'],bins=int(np.sqrt(len(results_perm['val']))))
plt.axvline(obs_acc['obs_test_acc'],c='r',label=None)
plt.xlabel('Accuracy')
plt.title('Chance Accuracy Distribution')
_=plt.annotate('Observed = %.3f' %(obs_acc['obs_test_acc']),
xy=(obs_acc['obs_test_acc'],9.75),
xytext=(0.6,10),
arrowprops={'color':'red'},
fontsize=14)
p_val = (np.sum(np.array(results_perm['val']) > obs_acc['obs_test_acc'])+1)/(len(results_perm['val'])+1)
print('Accuracy')
print('Observed: %.2f'%obs_acc['obs_test_acc'])
print('Chance: %.2f'%np.mean(results_perm['val']))
print('Observed > Chance (p = %.4f)' %(p_val))
Accuracy
Observed: 0.83
Chance: 0.50
Observed > Chance (p = 0.0099)
3.4. Comparision with Random Forest¶
As GRU belongs to the family of recurrent neural networks, it learns class separability from the sequential aspect of the data. Since the data used in this project is fMRI time-series data, GRU was a reasonable model choice. An interesting question that can be asked is, how well would a model that does not take into account the sequential aspect of the data perform? Would it perform as well as the GRU model? Or would it perform poorly? To make this comparison, a Random Forest classifier was trained on the current data. The Random Forest classifier was also fine tuned using the nested cross validation method, and best hyperparameters (n_estimators = 1500, max_feature = ‘sqrt’) were obtained. The test accuracy of Random Forest classifier was only 0.58 which is significantly low compared to that of the GRU model.
n_features = 316
features = ['feat%i'%i for i in range(1,n_features+1)]
# all participant IDs
participants = dataset_df.participant.unique()
'''
Reorganizing the data in the form of datafame to be compatible with
the format accepted by sklearn models
'''
df = pd.DataFrame()
for ii, row in dataset_df.iterrows():
tmp_df = pd.DataFrame(row["data"], columns = features)
tmp_df['subject'] = row["participant"]
tmp_df['timepoint'] = np.arange(7)+1
tmp_df['y'] = row["label"]
df = pd.concat([df,tmp_df],ignore_index=True)
def train_test_split(df):
'''
Splits the dataframe into train and test sets
X_train, X_test, y_train, y_test = train_test_split(df)
'''
train = df[df['subject'].isin(participants[dataset.train_idx])]
test = df[df['subject'].isin(participants[dataset.test_idx])]
return train[features], test[features], train['y'], test['y']
# Split data into train (42 participants) and test (19 participants)
X_train, X_test, y_train, y_test = train_test_split(df)
# Cross-validate Random forest classifier
rfc_path = '../../models/00-ROI316_last_segment/rf_classifier.joblib'
if os.path.exists(rfc_path):
rfc = load(rfc_path)
else:
rfc = RandomForestClassifier(1500,max_features="sqrt")
# Re-train and test the classifier
rfc.fit(X_train,y_train)
print('Random forest test accuracy: %.2f'%rfc.score(X_test,y_test))
Random forest test accuracy: 0.58
3.5. Temporal Trajectories¶
GRU outputs hidden states that are typically high dimensional. Hidden states (\(h_{t}\)) capture spatio-temporal variance that is most useful in maintaning class separability. To visualize dynamics, \(h_{t}\) was linearly projected onto a lower (3D) dimensional space, \(\hat{h_{t}}\). This was done by replacing the output layer with a Dimensionality Reduction Dense Layer (DRDL) with three linear units. In essence, this is a supervised non-linear dimensional reduction step.
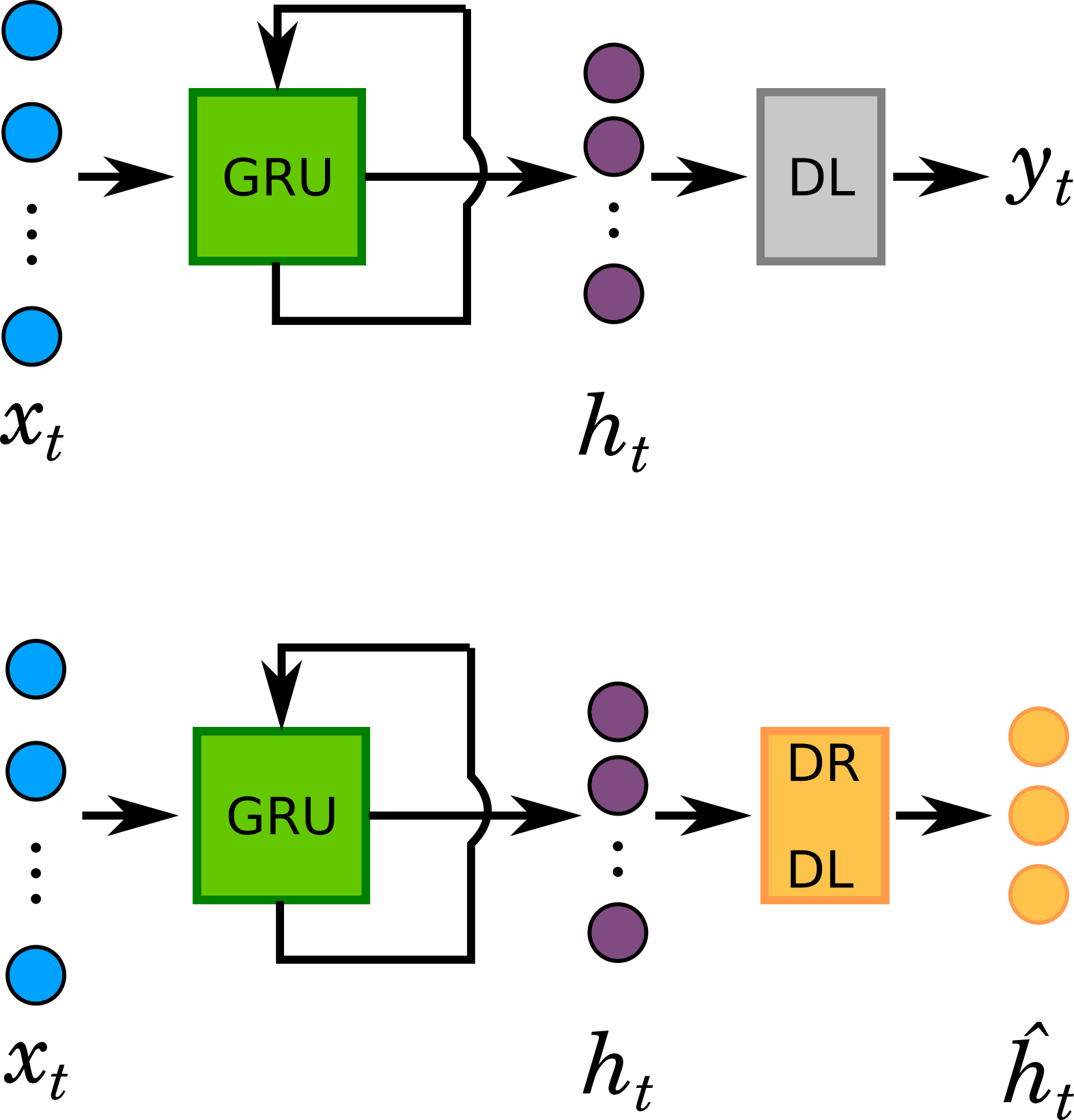
The 3-dimensional representations of \(h_{t}\) (\(\hat{h_{t}}\)) for both stimulus class are plotted along the three axes of the coordinate system below. The plot represents the temporal trajectories of the two classes. At the first timepoint the two classes are closest to each other. Distance between them increases with every timepoint. Next plot shows the Euclidean distance between the two classes as a function of time.
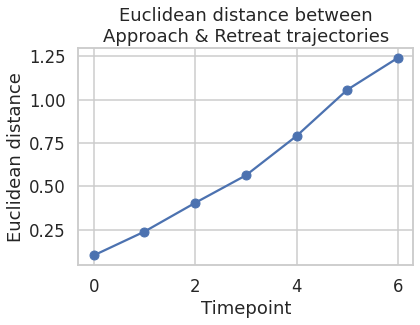
3.6. Conclusion¶
The above trajectories and Euclidean distance plots suggest that the GRU architecture is able to characterize distinct spatio-temporal patterns in the fMRI data, for appraoching and retreating threats.
3.7. Demonstration¶
The following video clip demonstrates model performance on one of the held out participant’s fMRI data. The video shows the visual paradigm presented to the participant during his/her fMRI scan, along with model predictions at the top-right of the screen. Prediction is either “Approach” or “Retreat”. If the prediction is correct, the color of the text remains green; and if it is incorrect, it turns red. Note that when the circles touch, the screen turns white and a red wheel appears around the circles to indicate delivery of the physical shock. Also note that the speed of the video has been increased by 4x for quick demonstration purposes.